Я много слышал о семантической сети, но я все еще не совсем уверен, что это такое. Как это будет отличаться от сети, которую мы знаем сейчас?
Что такое семантическая сеть?

Ответ 1
Как он будет отличаться от сети, которую мы знаем сейчас?
В настоящее время HTML + CSS больше ориентируется на структуру и представление. Семантика о значении означает. В семантической сети вы используете общие онтологии для определения смысла (семантики) объекта и значения отношений между объектами. Наиболее известными онтологиями являются FOAF и Dublin Core.
Обычно семантика выражается на специализированном языке, например RDF или OWL. RDF может быть встроен в XHTML с помощью eRDF или W3C RDFa.
Менее структурированная альтернатива eRDF/RDFa microformats.
Подробнее: http://en.wikipedia.org/wiki/Semantic_web
Ответ 2
Лучшее объяснение - пример. Попробуйте googling для всех автомобилей, рекламируемых в Интернете, с двигателями объемом менее 2.0 литров, которые запускают unleaded, и имеют mp3-соединение и могут быть замечены в демонстрационном зале удобно доступный на общественном транспорте из моего дома.
Google просто не сможет помочь вам с этим запросом, а не на самом деле. Вы должны сделать несколько поисков и самостоятельно соотнести результаты. В Semantic web вы сможете выразить интерес к продуктам для продажи, которые являются автомобилями, и добавить ограничения. Каждый результат был бы полезен. Один или несколько пользовательских интерфейсов могут позволить вам сделать это, некоторые из них могут быть специализированными, а другие - универсальными.
Другой пример, создающий диаграмму вещей, которые обычно не хранятся в одном месте, говорит о популярности диетического кокса или прогулок по стране в популяции по сравнению с уровнями клинического ожирения в одной и той же популяции. Для этого вы вообще не можете использовать веб-браузер, но можете использовать нечто похожее на Excel - но семантическая сеть предоставляет вам инструменты (SPARQL, RDF ) для поиска и обработки данных, которые там есть и доступны через HTTP.
Итак, точка, сделанная Bravax, не совсем верна, не так много может измениться - вы можете просто получить более полезные и лучшие веб-сайты mashup. Или вы можете найти себе множество вещей, о которых вы никогда не думали, как о связи с сетью до сегодняшнего дня.
В текущей сети есть много альтернатив для выполнения одной и той же вещи, например, Animated GIF, Flash, Silverlight, DHTML и т.д. Для размещения данных в семантической сети будет представлен целый ряд инструментов и форматов. RDFa - хороший, более общий тип микроформата, но вы можете предоставить дамп всей базы данных, выставить конечная точка SPARQL, используйте микроформат или проприетарную структуру HTML и добавьте преобразование, там будет много инструментов для разных случаев.
Итак, Vartec также частично прав, вы можете использовать RDFa и eRDF, но вы также можете использовать множество других вещей для публикации данных.
Обратите внимание, что существует много перекрытий между семантической сетью и другой концепцией simper, называемой Связанные данные. Как они соотносятся друг с другом, неясно, но мое восприятие этого заключается в том, что веб-сайт Linked Data - это то, что вам нужно, прежде чем инструменты и методы Semantic Web будут иметь что-то делать. Связанные данные касаются данных, семантическая сеть - это больше о обработке данных, рассуждении о ней и решении таких проблем, как надежность доверия и т.д. По сути, нижние несколько слоев стек технологий.
Ответ 3
Семантический Интернет - это очень простая идея. (Как и все хорошие).
В настоящее время Сеть состоит из документов со ссылками между ними. Google сделал довольно хороший бизнес из контекста и привязал текст в ссылках, чтобы выяснить, что означают ссылки, и создать механизм для извлечения данных на основе этого. Другими словами, Google оценивает смысл семантического значения ссылки.
Идея Semantic Web - "что, если эти ссылки были напечатаны?" Каждый факт в Интернете получает адрес - URI - и связан с другими фактами (также URI) отношениями (также URI). Группы отношений называются "онтологиями".
Таким образом, вместо ссылок на страницы A на странице B, например, в текущей сети, ссылки в семантической сети больше похожи:
URI Ссылки на URI B со ссылкой типа URI C.
Все, что может иметь URI. У людей могут быть URI; обычно мы используем набор отношений, называемых FOAF для их описания. Итак, пусть URI для Джеффа Этвуда http://codinghorror.com/foaf.xml; то вы могли бы сказать:
< http://codinghorror.com > < http://xmlns.com/foaf/0.1/homepage > < http://codinghorror.com/foaf.xml >
т.е. http://codinghorror.com является домашней страницей лица, представленного содержимым http://codinghorror.com/foaf.xml.
Теперь машины могут читать и запрашивать эти отношения - поэтому вы превращаете Web в базу данных, с которой компьютеры могут немедленно что-то делать. Язык запросов Semantic Web - это SPARQL, и стоит проверить его.
Ответ 4
Семантический веб - это просто - семантический (значимый) слой поверх WWW. Он полуструктурирован (RDF), он самоописателен (онтологии с использованием OWL) и позволяет открывать ресурсы (SPARQL).
Semantic Web работает на основе предположения "открытого мира"; просто потому, что что-то не указано, не означает, что оно не существует, оно просто "неизвестно". Это принципиально другая логика, используемая в СУБД, например MySQL и др. - если чего-то не хватает, этого не существует - предположения "Закрытый мир". Пролог и DATALOG являются хорошими примерами логики Close World.
Если вы хотите действительно узнать, что происходит внизу, вам нужно посмотреть на его основы, которые лежат в описании логики. Хороший обзор описания логики можно найти здесь: http://www.inf.unibz.it/~franconi/dl/course/
Если вы хотите узнать больше о RDF, прочитайте RDF Primer. RDF Semantics - это еще одно риппинг-чтение.
Исследователи в основном отказались от "семантической" части Semantic Web и решили сосредоточиться на Linked Data - как можно трогать RDF-тройки, чтобы мы могли тратить больше интернет-трафика, -)
Ответ 5
В настоящее время с HTML-страницами есть метки разметки, которые описывают, как должен отображаться контент, <b>, '<pre> и т.д. Эти теги не подразумевают никакого смысла в их содержании.
Концепция семантической сети заключается в том, что документы будут содержать теги XML, которые подразумевают смысл их содержимого. Например <person><firstname>. Большая идея заключается в том, что CSS сможет отформатировать такие документы, но также можно будет легко извлечь значимую информацию из этих документов.
Ответ 6
Семантическая сеть - это то, что Тим Бернерс-Ли, изобретатель Всемирной паутины, действительно предназначил для Сети, то есть глобальный график взаимосвязанных данных. Это обобщение социального графа, где вы можете использовать социальные данные (со словарями типа FOAF), а также любой другой вид машиносчитываемых данных и соединить их друг с другом. Стандартными форматами для описания этой инфармации для машин является формат описания ресурсов (RDF) и язык веб-онтологии (OWL). В Сети уже много кодированных данных, включая версию Википедии RDF, называемую DBPedia.
Семантическая сеть будет отличаться от сегодняшней Сети на этих компьютерах, а также люди поймут, какие документы содержат, а также какое значение имеют ссылки между документами. Это облегчит автоматизацию задач обработки информации, в том числе исследование информации из достоверных источников. Полный пакет SemWeb включает криптографические, защищенные системы и сети доверия.
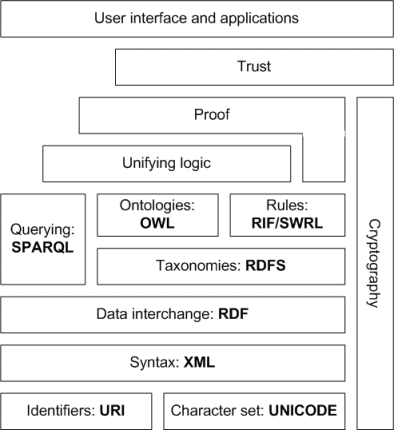{kind=link}
Ответ 7
Тим Бернерс-Ли описывает это в своем сообщении в блоге Гигантский глобальный график (с 2007-11-21):
Три умственных движения:
- Интернет: "Это не кабели, а интересные компьютеры"
- (World Wide) Веб: "Это не компьютеры, а интересные документы"
- Гигантский глобальный график: "Это не документы, это то, о чем они важны"
О термине "Гигантский глобальный график":
Теперь мы можем использовать слово Graph, чтобы отличить от Web.
Я назвал этот график Семантическим Web, но, возможно, это был Giant Global Graph! Чем хуже WWWW?;-) Не был установлен термин "семантический веб" в течение длительного времени, я не предлагаю его менять. Но подумайте о графике, который он есть. (Сноска: "График" также является словом, используемым спецификациями RDF, но это кстати. Хотя синтаксический анализатор XML создает дерево DOM, парсер RDF создает в памяти график RDF.)
Ответ 8
Семантическая сеть - единственное прагматическое решение, предлагаемое до сих пор для устранения недостатков дизайна в World Wide Web. Поскольку дизайнеры интернета, как мы его знаем сегодня, не обеспечили механизмов, которые бы затрагивали фундаментальные лингвистические феномены, которые определяют способ мышления и общения людей, таких как омонимия, синонимия и т.д. Поиск информации в Интернете приводит к потоку ложных позитивы. Идея семантической сети сводится к присвоению недвусмысленных идентификаторов веб-ресурсам, которые помогут правильно определить их значение. Если это удается в один прекрасный день, мы можем забыть, как выглядел обычный поиск Google, если он не работает, все останется таким, как сейчас.
Ответ 9
Это звуковое слово, чтобы привлечь интерес людей, Similiar to Web 2.0
т.е. В будущем контент будет разделен на презентацию, позволяющую много добра.
В действительности факты будут субъективными, в зависимости от правдоподобия и авторитета хозяина.
Другими словами, пользователи не будут видеть большой разницы с этого момента.
Ответ 10
Семантический Web - это распределенная информационная система, в которой взаимосвязанные данные публикуются как трижды по RDF по HTTP. Тройки RDF состоят из объекта, предиката и объекта, но могут иметь к ним другие вещи, такие как типы данных и аннотации о естественном языке объектов. В семантической сети URI используются как идентификаторы, так и адреса сетевых ресурсов.
Его отличие от Интернета, поскольку Интернет представляет собой распределенную информационную систему документов и интерфейсов приложений.