Недавний question, позволяют ли компиляторы заменить смену с плавающей запятой с умножением с плавающей запятой, вдохновили меня задать этот вопрос.
В соответствии с строгим требованием, чтобы результаты после преобразования кода были побито идентичны действительной операции деления,
тривиально видеть, что для двоичной арифметики IEEE-754 это возможно для делителей, которые являются степенью двух. До тех пор, пока
дивизора является представимым, умножая на обратный дивизор, доставляя результаты, идентичные делению. Например, умножение на 0.5 может заменить деление на 2.0.
Затем возникает вопрос, какие другие дивизоры работают с такими заменами, предполагая, что мы разрешаем любую короткую последовательность команд, которая заменяет деление, но работает значительно быстрее, одновременно предоставляя бит-идентичные результаты. В частности, допускают скомпилированные операции с множественным добавлением в дополнение к простому умножению. В комментариях я указал на следующий соответствующий документ:
Николас Брисебарре, Жан-Мишель Мюллер и Саурабх Кумар Райна. Ускорение правильно округленного деления с плавающей запятой, когда делитель известен заранее. IEEE Transactions on Computers, Vol. 53, № 8, август 2004 г., стр. 1069-1072.
Метод, предложенный авторами статьи, предкомпирует обратный дивизор y как нормализованную пару головы-хвоста z h: z l следующим образом: z h= 1/y, z l= fma (-y, z h, 1)/y. Позднее деление q = x/y затем вычисляется как q = fma (z h, x, z l * x). В документе приводятся различные условия, которые должен удовлетворять дивизор y для выполнения этого алгоритма. Как легко заметить, этот алгоритм имеет проблемы с бесконечностями и ноль, когда знаки головы и хвоста различаются. Что еще более важно, это не даст правильных результатов для очень малых по величине дивидендов x, потому что вычисление хвоста частного, z l * x, страдает от underflow.
В документе также делается ссылка на альтернативный алгоритм деления на основе FMA, впервые предложенный Питером Маркстайном, когда он был в IBM. Соответствующая ссылка:
Р. W. Markstein. Вычисление элементарных функций на процессоре IBM RISC System/6000. IBM Journal of Research and Development, Vol. 34, № 1, январь 1990 г., стр. 111-119
В алгоритме Маркштейна сначала вычисляется обратный rc, из которого формируется начальное частное q = x * rc. Затем остальная часть деления точно вычисляется с помощью FMA как r = fma (-y, q, x), а улучшенный, более точный коэффициент, наконец, вычисляется как q = fma (r, rc, q).
У этого алгоритма также есть проблемы для x, которые являются нулями или бесконечностями (легко обрабатываются с соответствующим условным исполнением), но исчерпывающее тестирование с использованием данных с одной точностью float IEEE-754 показывает, что оно обеспечивает правильное отношение по всем возможным дивидендам x для многих делителей y, среди этих многих маленьких целых чисел. Этот код C реализует его:
/* precompute reciprocal */
rc = 1.0f / y;
/* compute quotient q=x/y */
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
В большинстве архитектур процессоров это должно перевести в нераскрывающуюся последовательность инструкций с использованием либо предикатов, условных движений, либо инструкций типа выбора. Чтобы привести конкретный пример: для деления на 3.0f компилятор nvcc CUDA 7.5 генерирует следующий машинный код для GPU класса Kepler:
LDG.E R5, [R2]; // load x
FSETP.NEU.AND P0, PT, |R5|, +INF , PT; // pred0 = fabsf(x) != INF
FMUL32I R2, R5, 0.3333333432674408; // q = x * (1.0f/3.0f)
FSETP.NEU.AND P0, PT, R5, RZ, P0; // pred0 = (x != 0.0f) && (fabsf(x) != INF)
FMA R5, R2, -3, R5; // r = fmaf (q, -3.0f, x);
MOV R4, R2 // q
@P0 FFMA R4, R5, c[0x2][0x0], R2; // if (pred0) q = fmaf (r, (1.0f/3.0f), q)
ST.E [R6], R4; // store q
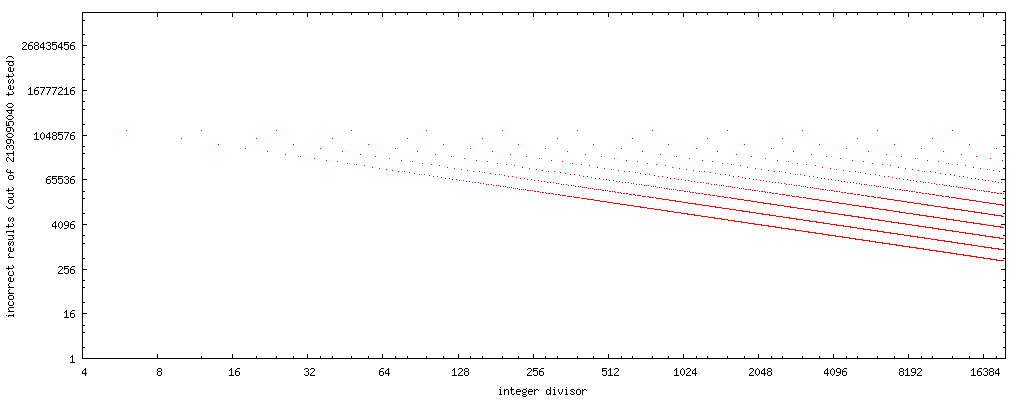
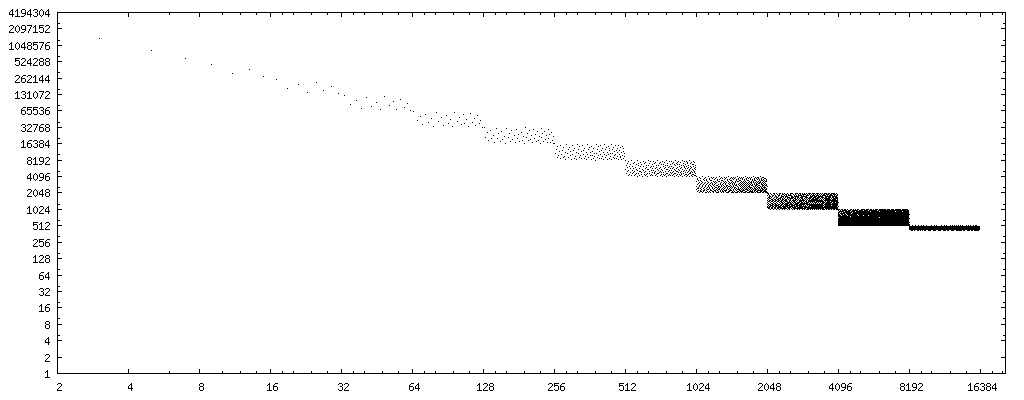
В моих экспериментах я написал крошечную тестовую программу C, показанную ниже, которая проходит через целые делители в порядке возрастания и для каждого из них исчерпывающе проверяет приведенную выше кодовую последовательность на правильное деление. Он печатает список делителей, прошедших этот исчерпывающий тест. Частичный вывод выглядит следующим образом:
PASS: 1, 2, 3, 4, 5, 7, 8, 9, 11, 13, 15, 16, 17, 19, 21, 23, 25, 27, 29, 31, 32, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 64, 65, 67, 69,
Чтобы включить алгоритм замены в компилятор в качестве оптимизации, белый список делителей, к которым безопасно применяется приведенное выше преобразование кода, является непрактичным. Вывод программы до сих пор (со скоростью около одного результата в минуту) указывает на то, что быстрый код работает правильно во всех возможных кодировках x для тех делителей y, которые являются нечетными целыми числами или являются степенями двух. Анекдотические доказательства, а не доказательство, конечно.
Какой набор математических условий может определить a-priori, безопасно ли преобразование деления на указанную выше последовательность кода? Ответы могут предполагать, что все операции с плавающей запятой выполняются в режиме округления по умолчанию "от раунда до ближайшего или даже".
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
int main (void)
{
float r, q, x, y, rc;
volatile union {
float f;
unsigned int i;
} arg, res, ref;
int err;
y = 1.0f;
printf ("PASS: ");
while (1) {
/* precompute reciprocal */
rc = 1.0f / y;
arg.i = 0x80000000;
err = 0;
do {
/* do the division, fast */
x = arg.f;
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
res.f = q;
/* compute the reference, slowly */
ref.f = x / y;
if (res.i != ref.i) {
err = 1;
break;
}
arg.i--;
} while (arg.i != 0x80000000);
if (!err) printf ("%g, ", y);
y += 1.0f;
}
return EXIT_SUCCESS;
}



{kind=link}
{kind=link}