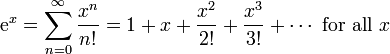Стандартное представление константы e как суммы бесконечного ряда очень малоэффективно для вычислений из-за многих операций деления. Итак, есть ли альтернативные способы эффективного вычисления константы?
Спасибо!
ИЗМЕНИТЬ
После выполнения некоторых из ваших ссылок я считаю, что эффективность исходит из метода, называемого бинарным расщеплением (в то время как представление все еще упоминается в серии), с которым я не знаком. Если кто-то знаком с этим, не стесняйтесь вносить свой вклад.