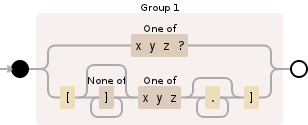
Я ищу подходящие шаблоны типа glob, похожие на то, что команда Redis KEYS принимает. Цитирование:
- h? llo соответствует привет, hallo и hxllo
- h * llo соответствует hllo и heeeello
- h [ae] llo соответствует привет и hallo, но не hillo
Но я не сопоставляюсь с текстовой строкой, но сопоставляю шаблон с другим шаблоном со всеми операторами, имеющими смысл на обоих концах.
Например, эти шаблоны должны совпадать друг с другом в одной строке:
prefix* prefix:extended*
*suffix *:extended:suffix
left*right left*middle*right
a*b*c a*b*d*b*c
hello* *ok
pre[ab]fix* pre[bc]fix*
И они не должны совпадать:
prefix* wrong:prefix:*
*suffix *suffix:wrong
left*right right*middle*left
pre[ab]fix* pre[xy]fix*
?*b*? bcb
Так что мне интересно...
- если это возможно (реализовать алгоритм проверки), если вообще?
- Если это невозможно, какое подмножество регулярного выражения было бы возможно? (то есть запретить * подстановочный знак?)
- если это действительно возможно, что является эффективным алгоритмом?
- Какова требуемая временная сложность?
РЕДАКТИРОВАТЬ: нашел этот другой вопрос о подмножестве RegEx, но это не совсем то же самое, что слова hello* и *ok matches не является подмножеством/надмножеством друг друга, но они пересекаются.
Итак, математически я предполагаю, что это можно сформулировать так: можно ли детерминистически проверить, что набор слов, которые соответствует одному шаблону, пересекающийся с набором слов, который соответствует другому шаблону, приводит к непустому набору?
EDIT: Друг @neizod составил эту таблицу устранения, которая аккуратно визуализирует то, что может быть потенциальным/частичным решением: Правило исключения
EDIT: добавит дополнительную награду для тех, кто может также предоставить рабочий код (на любом языке) и тестовые примеры, подтверждающие его.
РЕДАКТИРОВАТЬ: Добавлено? * b *? тест, обнаруженный @DanielGimenez в комментариях.