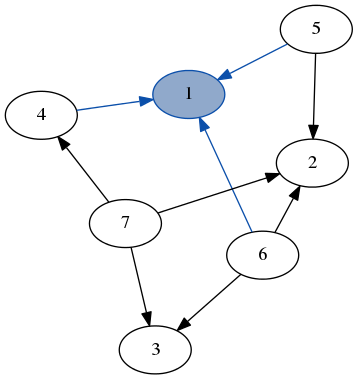
Функциональная глубина первого поиска прекрасна в ориентированных ациклических графах.
Однако в графах с циклами, как избежать бесконечной рекурсии? На процедурный язык я бы отмечал узлы, когда я их ударил, но позвольте сказать, что я не могу этого сделать.
Список посещаемых узлов возможен, но будет медленным, потому что использование одного приведет к линейному поиску этого списка до повторения. Лучшая структура данных, чем список здесь, очевидно, поможет, но это не цель игры, потому что я кодирую в ML - списки - это король, и все, что мне придется писать.
Есть ли разумный способ решения этой проблемы? Или мне придется делать с посещенным списком или, богом запретить, изменчивое состояние?


{kind=link}