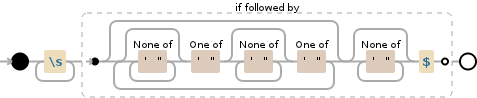
Я не очень хорошо разбираюсь в RegEx, может ли кто-нибудь дать мне регулярное выражение (для использования на Java), которое выберет все пробелы, которые не находятся между двумя кавычками? Я пытаюсь удалить все такие пробелы из строки, поэтому любое решение для этого будет работать.
Например:
(это тестовое предложение для регулярного выражения)
должен стать
(thisisatest "предложение для регулярного выражения" )