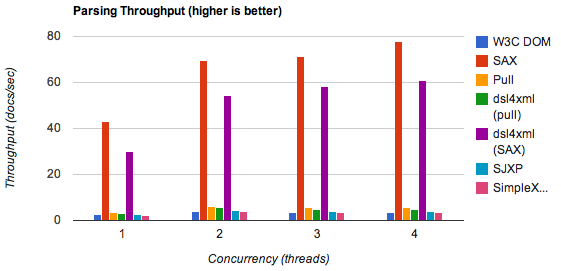
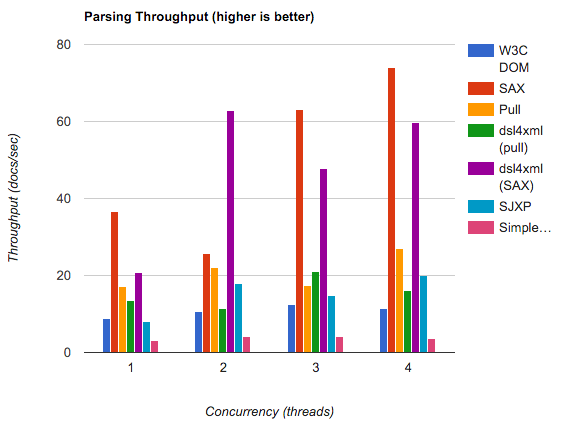
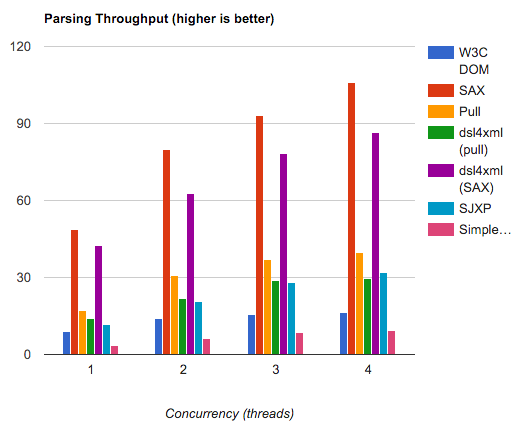
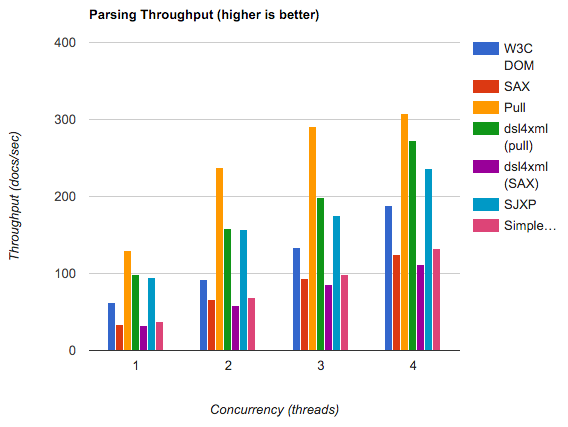
Мне нужно прочитать XML файл с примерно 4000 строк на Android. Сначала я попробовал SimpleXML library, потому что это было проще всего, и мне потребовалось около 2 минут на моем HTC Desire. Поэтому я подумал, что SimpleXML настолько медленный из-за отражения и всей магии, что использует эта библиотека. Я переписал свой парсер и использовал встроенный метод разбора DOM с особым вниманием к производительности. Это немного помогло, но все равно потребовалось около 60 секунд, что по-прежнему совершенно неприемлемо. После небольшого исследования я нашел эту статью на developer.com. Есть несколько графиков, которые показывают, что два других доступных метода - парсер SAX и Android Pull-Parser - одинаково медленны. И в конце статьи вы найдете следующее утверждение:
Первый сюрприз, который я имел, заключался в том, насколько медленны все три метода. пользователей не хотят долго ждать результатов на мобильных телефонах, поэтому синтаксический анализ более чем несколько десятков записей могут указывать на другой метод.
Что может быть "другим методом"? Что делать, если у вас больше, чем "несколько десятков записей"?