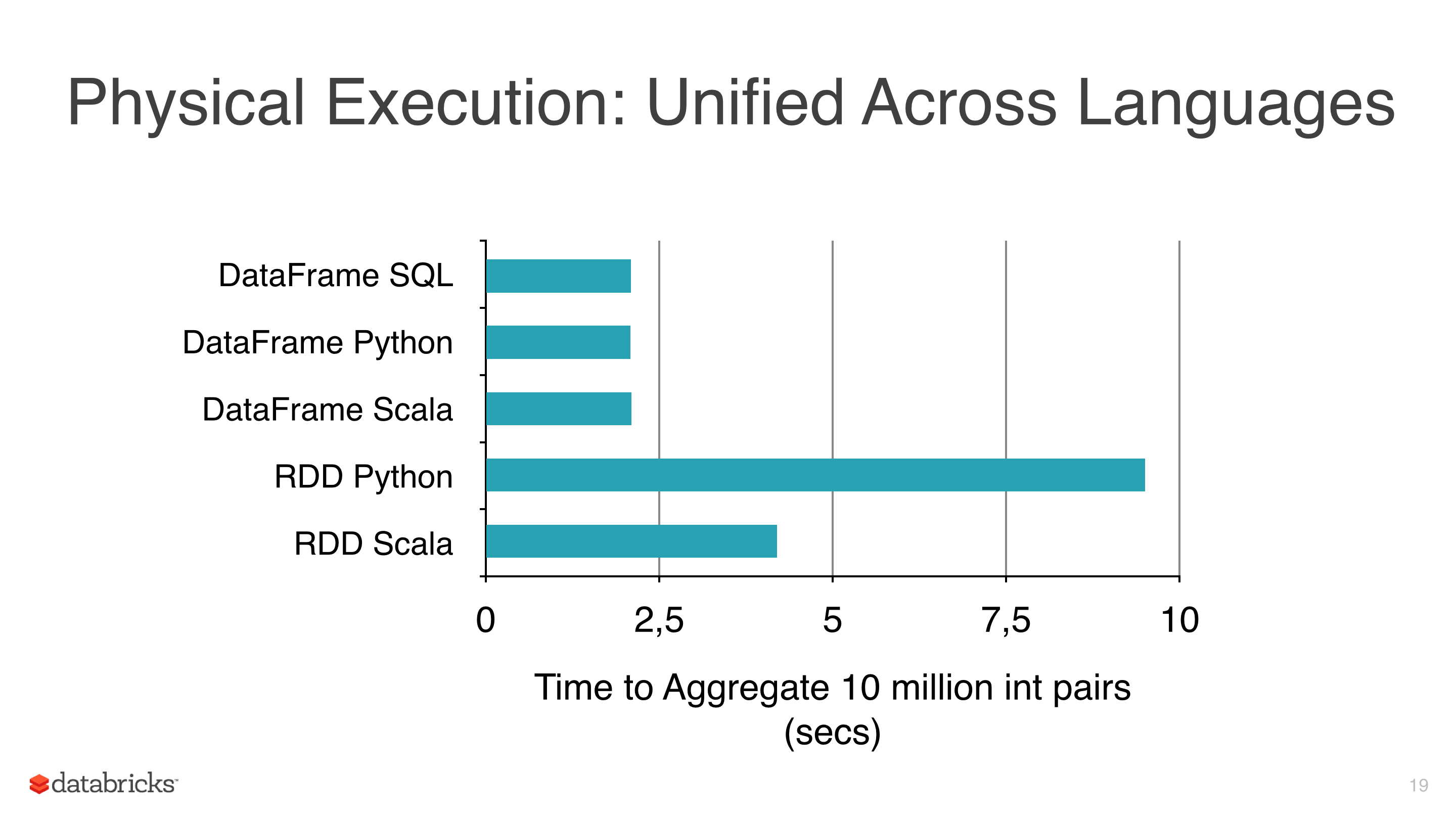
Я применял некоторые машинные алгоритмы машинного обучения, такие как линейная регрессия, логистическая регрессия и Наивные байесы к некоторым данным, но я пытался избежать использования RDD и начать использовать DataFrames, потому что RDD медленнее, чем Dataframes под pyspark (см. рис. 1).
Другая причина, по которой я использую DataFrames, состоит в том, что библиотека ml имеет класс, очень полезный для настройки моделей, которые CrossValidator этот класс возвращает модель после установки он, очевидно, этот метод должен протестировать несколько сценариев, а затем возвращает установленную модель (с наилучшими комбинациями параметров).
Кластер, который я использую, не так велик, и данные довольно большие, и некоторые из них занимают часы, поэтому я хочу сохранить эти модели, чтобы повторно использовать их позже, но я не понял, как, я чего-то игнорирую?
Примечания:
- Классы модели mllib имеют метод сохранения (т.е. NaiveBayes), но mllib не имеет CrossValidator и использует RDD, поэтому я избегаю его преднамеренно.
- Текущая версия - искра 1.5.1.
