Я хочу многократно искать значения в массиве, который не изменяется.
До сих пор я делал это так: я помещал значения в хэш (поэтому у меня есть массив и хеш с по существу одним и тем же содержимым), и я ищу хэш с помощью exists.
Мне не нравятся две разные переменные (массив и хэш), которые сохраняют одно и то же; однако хэш намного быстрее для поиска.
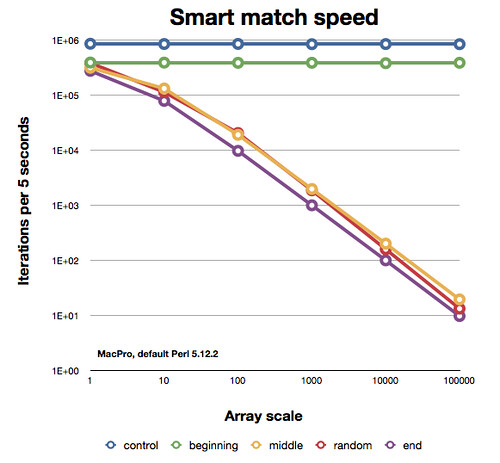
Я узнал, что в Perl 5.10 есть оператор ~~ (smartmatch). Насколько это эффективно при поиске скаляра в массиве?