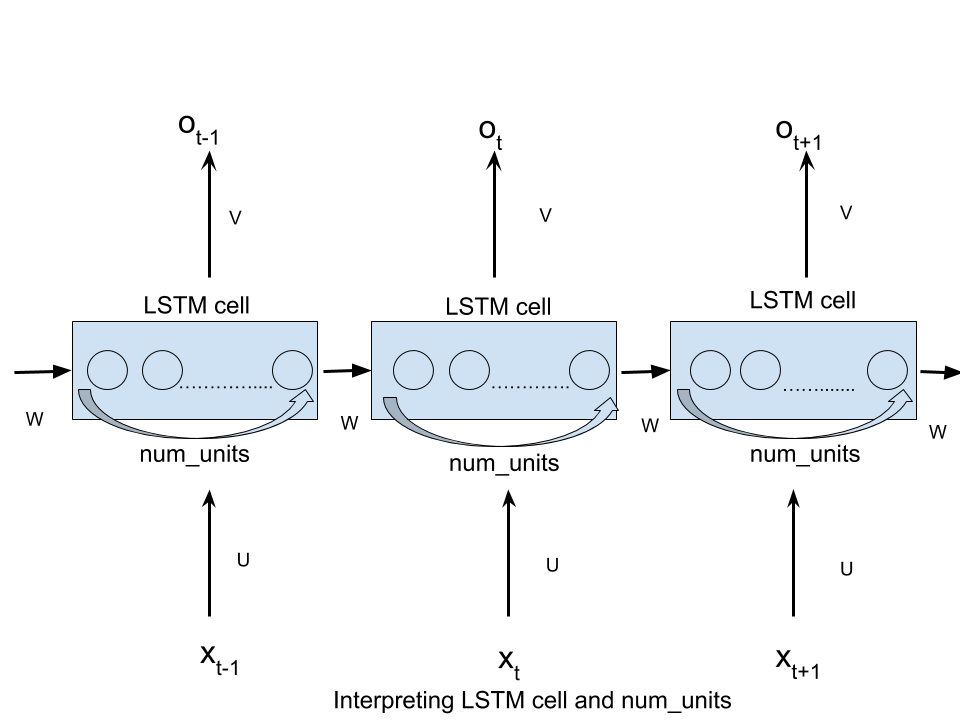
В примерах MNIST LSTM я не понимаю, что означает "скрытый слой". Это сформированный воображаемый слой, когда вы представляете развернутый RNN со временем?
Почему в большинстве случаев num_units = 128?
Я знаю, что я должен подробно прочитать блог колы, чтобы понять это, но до этого я просто хочу получить код, работающий с данными временного ряда, которые у меня есть.







{kind=link}