Я видел несколько подобных вопросов, но я хотел бы задать свой конкретный вопрос так, как только могу:
У меня есть график рассеяния с переменной "z", закодированной в цветовой шкале:
library(ggplot2)
myData <- data.frame(x = rnorm(1000),
y = rnorm(1000))
myData$z <- with(myData, x * y)
badVersion <- ggplot(myData,
aes(x = x, y = y, colour = z))
badVersion <- badVersion + geom_point()
print(badVersion)
Что производит это: 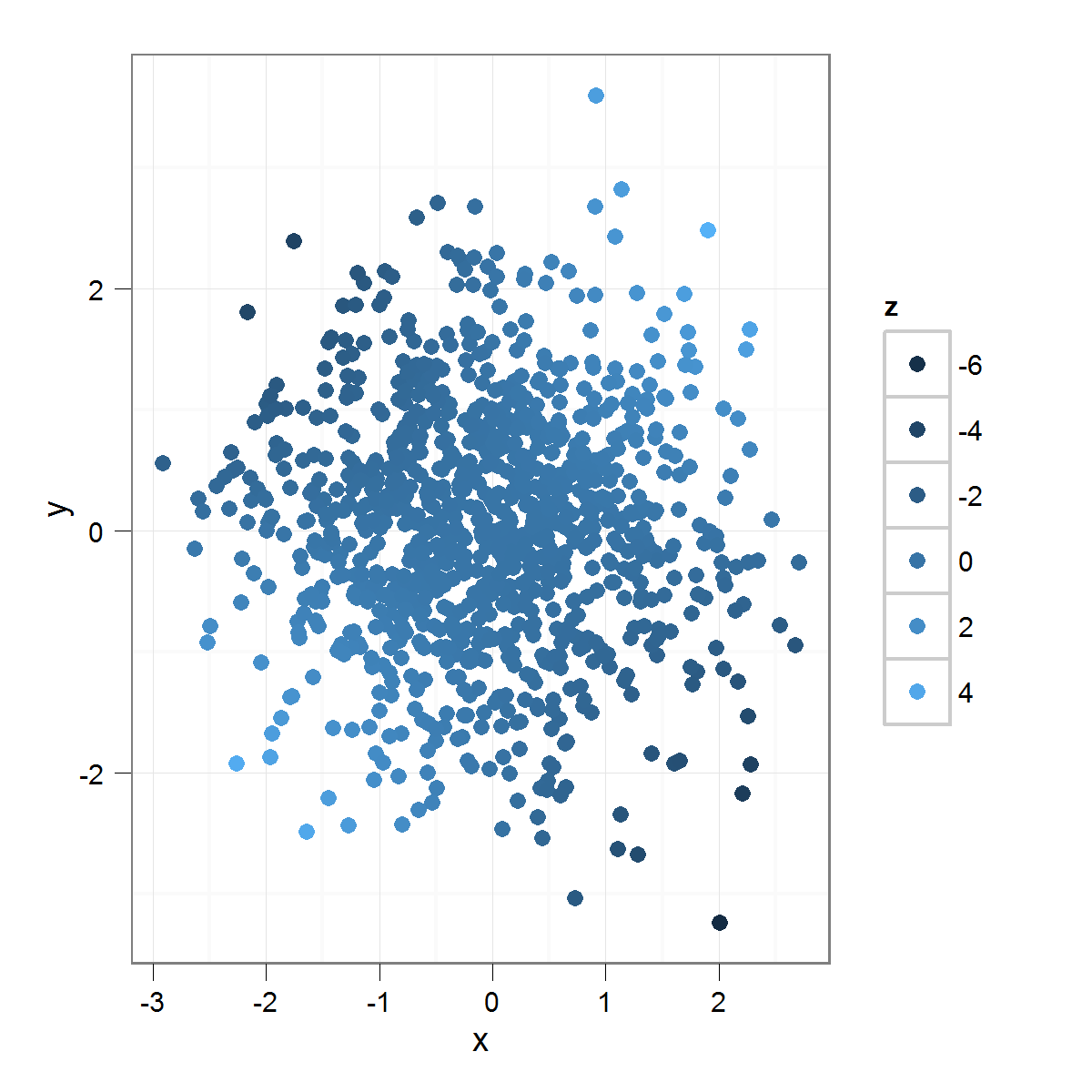
Как вы можете видеть, так как переменная "z" обычно распределяется, очень немногие из точек окрашены "экстремальными" цветами дистрибутива. Это так, как должно быть, но я заинтересован в том, чтобы подчеркнуть разницу. Один из способов сделать это - использовать:
betterVersion <- ggplot(myData,
aes(x = x, y = y, colour = rank(z)))
betterVersion <- betterVersion + geom_point()
print(betterVersion)
Что производит это: 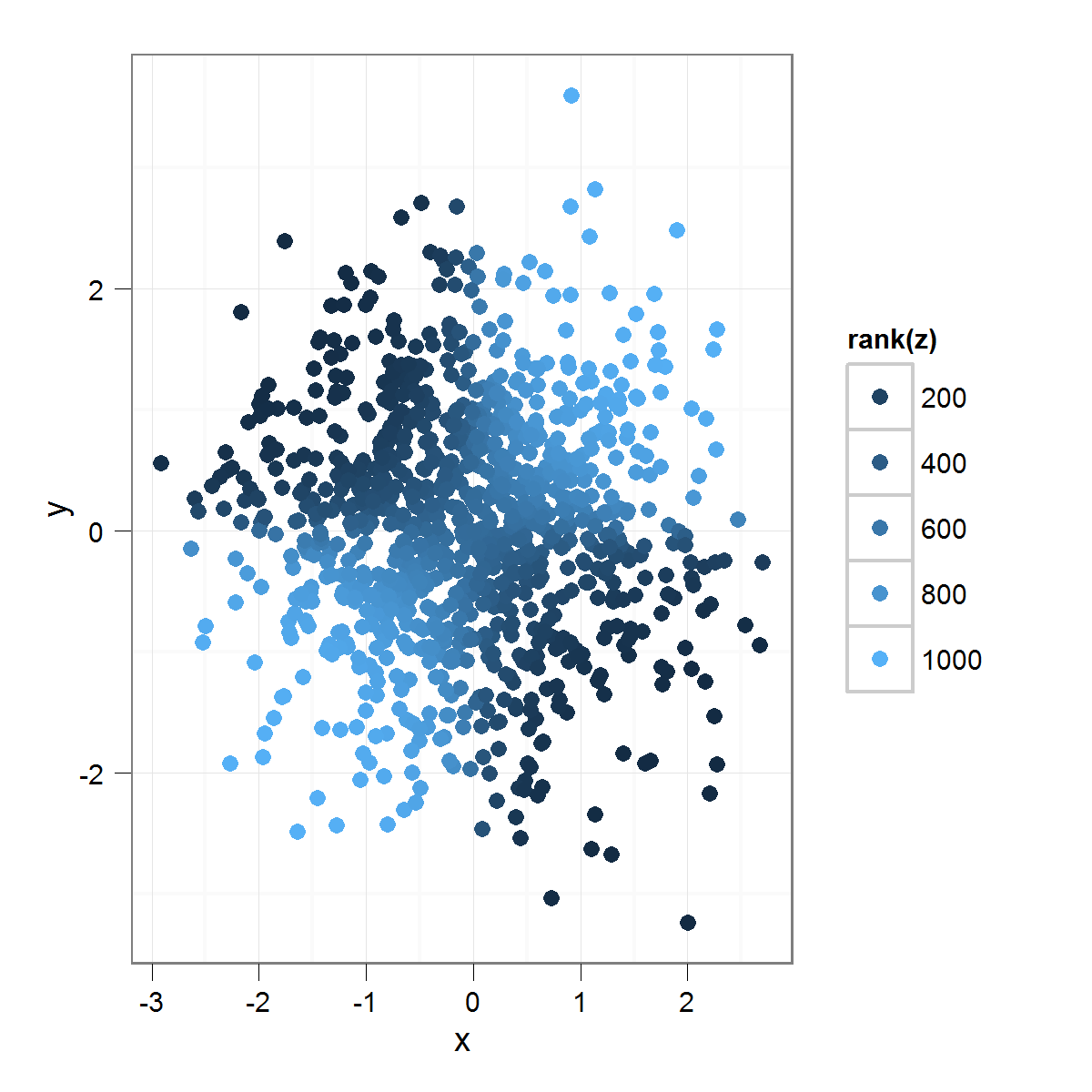
Применяя rank() к переменной "z", я получаю гораздо больший акцент на незначительных различиях в переменной "z". Можно предположить, что здесь можно использовать любое преобразование вместо ранга, но вы получаете идею.
Мой вопрос заключается, по сути, в том, что является самым простым способом или самым "истинным ggplot2" способом получения легенды в исходных единицах (единицы z, в отличие от ранга z), при сохранении преобразованная версия цветных точек?
У меня такое чувство, что использование rescaler() каким-то образом, но мне не ясно, как использовать rescaler() с произвольными преобразованиями и т.д. В целом, более понятные примеры были бы полезны.
Заранее благодарим за ваше время.


