Поэтому я думаю, что меня похоронят, чтобы задать такой тривиальный вопрос, но я немного смущен.
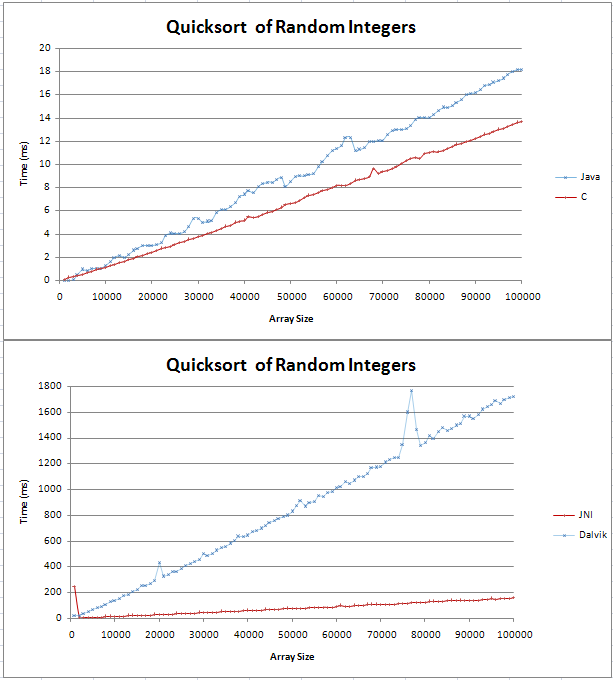
Я реализовал quicksort в Java и C, и я делал некоторые базовые сравнения. График выходил как две прямые линии, причем C был на 4 мс быстрее, чем Java-аналог более 100 000 случайных чисел.
Код моих тестов можно найти здесь;
Я не был уверен, что будет выглядеть строка (n log n), но я не думал, что это будет прямо. Я просто хотел проверить, что это ожидаемый результат, и что я не должен пытаться найти ошибку в моем коде.
Я вложил формулу в excel, а для основания 10 это кажется прямой линией с изломом в начале. Это потому, что разница между log (n) и log (n + 1) линейно возрастает?
Благодаря,
Гав

