У меня есть программа, которая должна многократно вычислять приблизительный процентиль (статистика заказа) набора данных, чтобы удалить выбросы перед дальнейшей обработкой. В настоящее время я делаю это путем сортировки массива значений и выбора соответствующего элемента; это выполнимо, но это заметная ошибка в профилях, несмотря на то, что она является довольно небольшой частью программы.
Дополнительная информация:
- Набор данных содержит порядка 100000 чисел с плавающей запятой и считается "разумно" распределенным - вряд ли будут дублирования или огромные спайки плотности вблизи определенных значений; и если по какой-то нечетной причине распределение является нечетным, то ОК для приближения будет менее точным, так как данные, вероятно, перепутаны во всяком случае и дальнейшей обработке сомнительной. Однако данные не обязательно равномерно или нормально распределены; это очень маловероятно, чтобы быть вырожденным.
- Приближенное решение будет прекрасным, но мне нужно понять, как приближение вводит ошибку, чтобы убедиться, что оно действительно.
- Поскольку цель состоит в том, чтобы удалить выбросы, я вычисляю два процентиля по тем же данным во все времена: например, один на 95% и один на 5%.
- Приложение находится на С# с битами тяжелого подъема в С++; псевдокод или существовавшая ранее библиотека в любом случае будет прекрасной.
- Совершенно другой способ удаления выбросов будет также хорош, если это разумно.
- Обновление: Кажется, я ищу приближенный алгоритм выбора.
Хотя это все сделано в цикле, данные (немного) разные каждый раз, поэтому нелегко повторно использовать структуру данных, как это было сделано для этого вопроса.
Реализованное решение
Используя алгоритм выбора википедии, предложенный Гронимом, сократил эту часть времени выполнения примерно на 20 раз.
Поскольку я не мог найти реализацию С#, вот что я придумал. Это быстрее даже для небольших входов, чем Array.Sort; и на 1000 элементов он в 25 раз быстрее.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
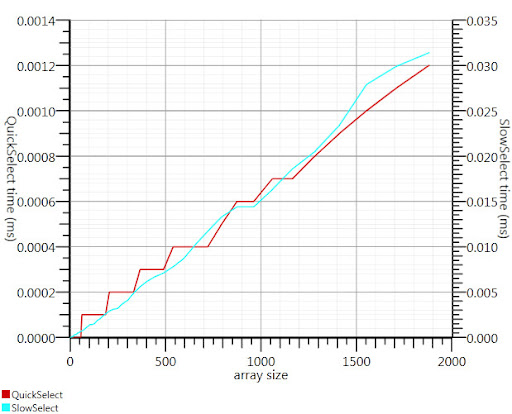
Спасибо, Гроним, за то, что указал мне в правильном направлении!
